之前偶然拿到一台大麦DW22D路由器,应该是之前的租客办长城宽带赠送的,登入管理界面发现里面是基于长城宽带深度定制的系统。
上了恩山查了一下发现这个机器的硬件还可以,并且可以无拆机刷入padavan固件,所以就开始按照教程刷机。
无拆机刷机
以下步骤参考恩山的教程。
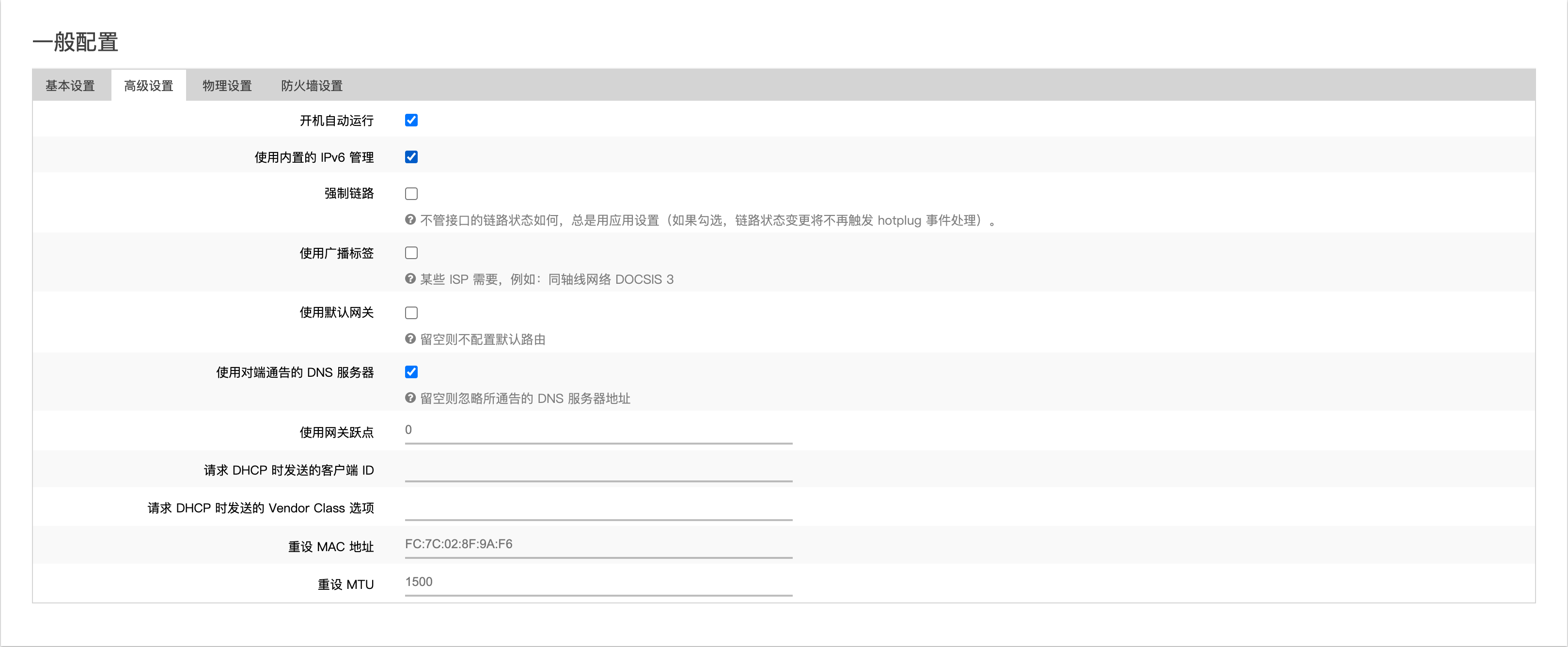
开启ssh
本方法主要依靠后门页面的命令注入漏洞,步骤如下:
注入新密码
电脑连上路由器(最好有线方式),访问http://192.168.10.1/upgrade.html,在页面上打开ssh的选项,密码框内输入:
123 | echo 6c216b27c8c9b051106c969e2077d4e9 > /ezwrt/bin/upgrade_passwd
注意末尾有空格。这里的md5值是echo dfc643 | md5算出来的,里面的dfc643是发现这个方法大佬的用户名,此处的密码是可以随便改的。然后点确定提交,此时会提示密码错误,可以忽略。
注入ssh公钥
再次访问http://192.168.10.1/upgrade.html,同样选择打开ssh,密码框内输入:
123 | echo YOUR_ID_RSA_PUB > /etc/dropbear/authorized_keys
同样注意末尾有空格。其中YOUR_ID_RSA_PUB替换为自己的公钥,即电脑上~/.ssh/id_rsa.pub的内容。再次点确定提交,此时还会提示密码错误,也可以忽略。
开启ssh
最后一次访问http://192.168.10.1/upgrade.html,选择打开ssh,密码为dfc643(如果在第一步注入密码时用了别的密码,此处输入相应的密码),最后点确定提交,提示start ssh success表示已经开启ssh。
这样就可以ssh [email protected]登录路由器了。
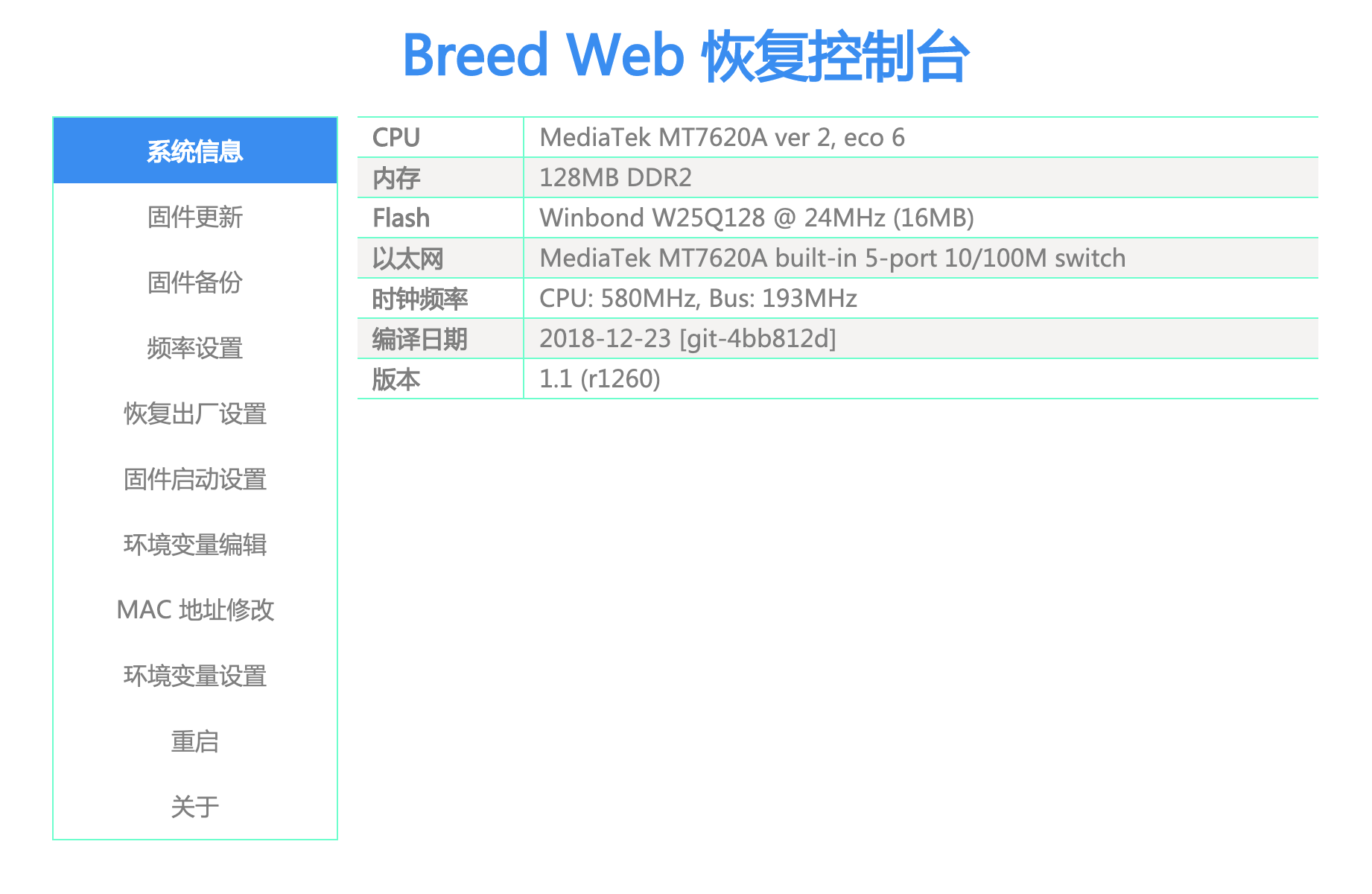
刷入breed
breed是hackpascal独立开发的一个全新的 Bootloader。DW22D路由器对应的版本是breed-mt7620-reset13.bin。
下载好后将其传入路由器的/tmp目录下备用:
scp breed-mt7620-reset13.bin [email protected]:/tmp
然后在路由器上执行:
mtd_write -x mIp2osnRG3qZGdIlQPh1 -r write /tmp/breed-mt7620-reset13.bin bootloader
这样应该就能将breed刷入bootloader,然后就可以随意刷firmware了。
然而我手残将最后的bootloader打成了firmware,也就是将breed刷入了firmware分区,导致路由器进不去系统了,也才有了后面的ttl救砖。
TTL刷机
以下步骤参考恩山的教程。
USB转TTL
为了让路由器硬件和电脑相连,需要一个USB转TTL模块,随便在马云家买一个最便宜的就能用,我就买了一个ch340g芯片的模块。
TTL驱动
然后在github找了驱动安装上(这里给的是Mac电脑的驱动,Windows的驱动一般卖家都会提供,网上找找也都有)。
重启后打开网络偏好可以看见多了一个串行接口:
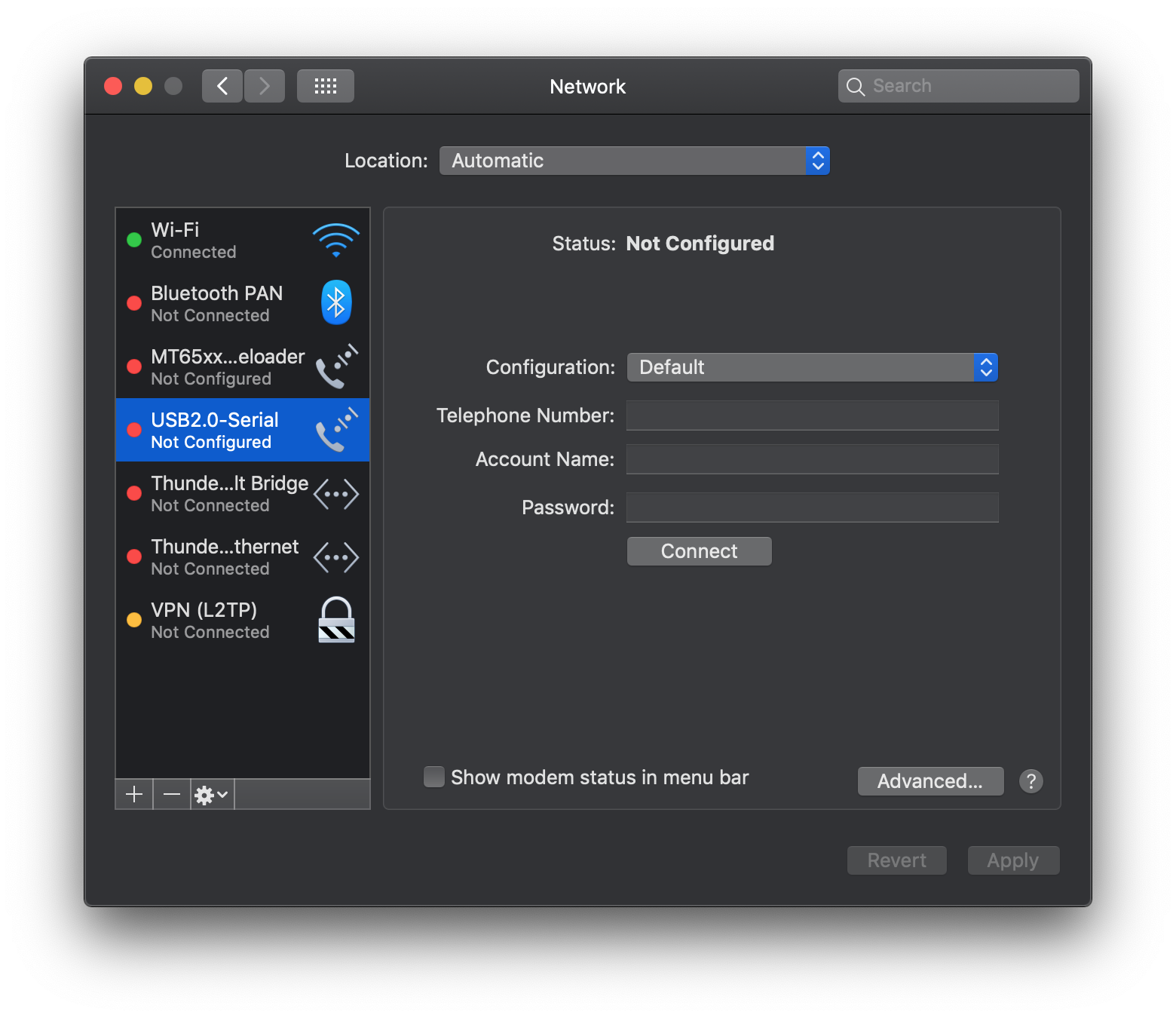
将USB转TTL模块插在电脑上,在/dev目录下会出现名字类似cu.usbserial-1410的设备,说明识别成功。
TTL连接
在如图位置焊上引脚(GND那个孔不用焊):

然后用杜邦线将三个引脚和USB转TTL模块相连。
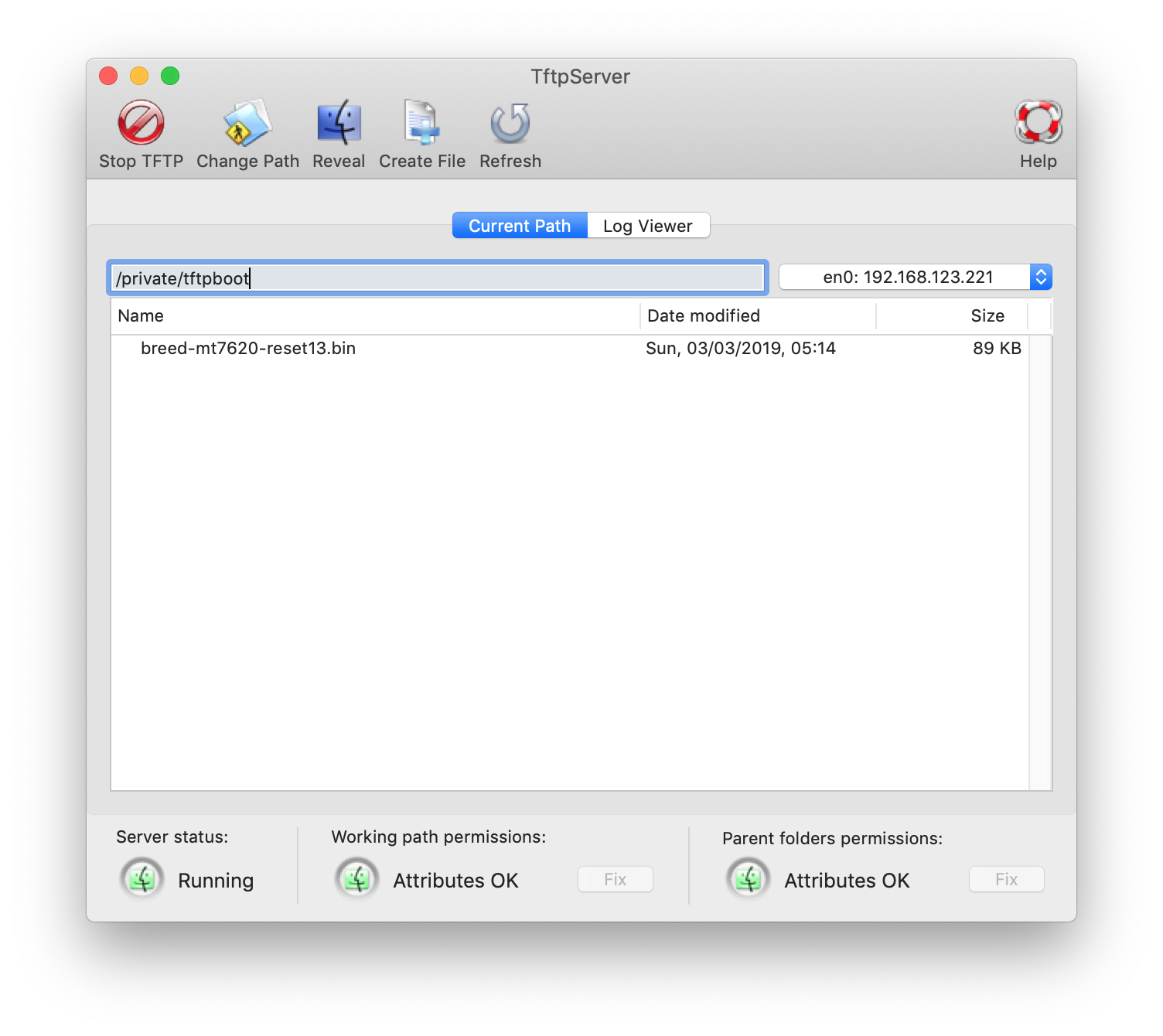
开启TFTP
将电脑用网线和路由器lan口连接,设置有线连接为手动模式,按图修改参数:
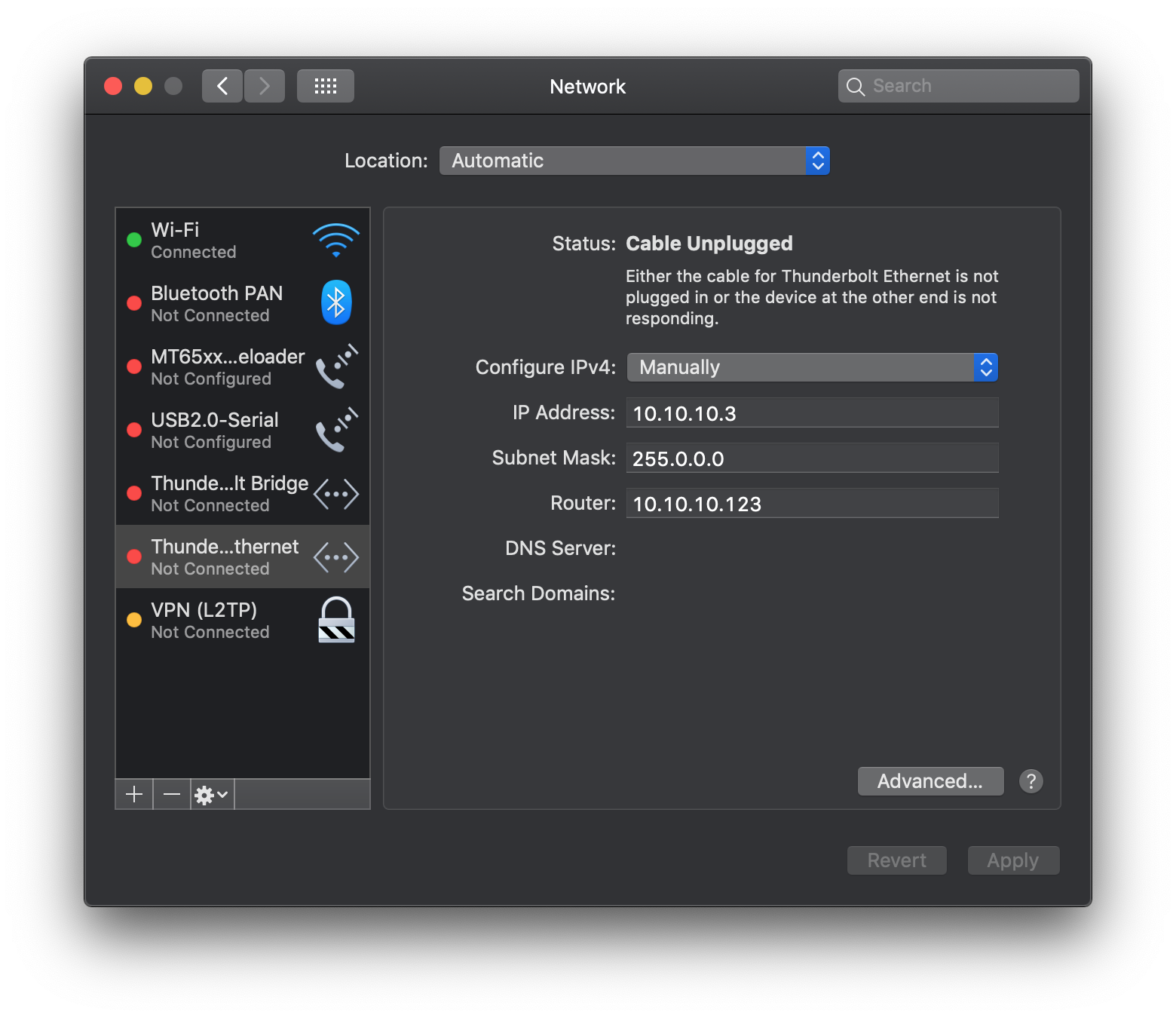
参考macOS启用TFTP服务,将breed-mt7620-reset13.bin放到TFTP目录下,将TFTP的地址选择有线ip(即上面设置的10.10.10.3)。
刷机
一切就绪后,可以连接路由器开始刷机。
登录路由器
使用screen连接未通电的路由器,波特率为57600:
screen /dev/cu.usbserial-1410 57600
此时终端里什么也没有。然后给路由器通电,此时会打印出很多东西,最后出现一些选项,立刻(5秒内)按数字键9选择TFTP刷机。
刷入breed
之后会让确认device IP(路由器地址)和server IP(电脑地址),确认无误后会提示输入要刷入的文件名,输入breed-mt7620-reset13.bin回车就开始刷入了。
刷完后断电按住复位键通电并长按5秒即可进入breed: