
目录
原文:Efficient Estimation of Word Representations in Vector Space
源码:word2vec
摘要
本文提出了两种新的模型结构,用于计算大型数据集中单词的连续向量表征。这些表征的质量是在单词相似性任务中衡量出来的,并将结果与之前基于不同类型神经网络(neural network)的最佳效果进行比较。我们观测到在低计算成本的精度上有大幅提高,只用不到一天的时间从16亿单词中学到高质量的词向量。此外,我们展示了这些向量在衡量句法和词义相似性上保证了最先进的性能。
绪论
当今先进的自然语言处理系统与技术都把词作为原子单元。总是被用作词表的索引,而不去考虑词间的相似性。这样做的好处在于简单且健壮,而且观察到简单模型在大量数据上训练的性能优于复杂模型在少量数据上的训练。统计语言模型中的N-gram就是这样的典型例子,几乎可以在所有可用数据上训练(万亿词量)。
然而简单的技术在很多领域都有其局限性。例如相关领域内的自动语音识别数据是有限的,简单模型的性能通常取决于转录的高质量的语音数据的大小,通常只有几百万的词。在机器翻译中,很多语音的已有的语料库的大小也只有几十亿。因此,对这些基本技术的简单升级并不会带来很大的性能提升,我们不得不考虑更复杂的高级技术。
随着机器学习技术的发展,训练更大规模数据上的复杂模型成为可能,它们要远远超过那些简单模型。可能最成功的概念就是使用分布式词表征(distributed representations of words),例如基于神经网络的语言模型远优于N-gram模型。
本文目标
本文的主要目标是介绍一种能从几十亿的语料库与几百万的词表的巨大数据集中学习高质量词表征的技术。据我们所知,迄今为止没有任何一个框架能以50~100维的词向量成功训练上亿的词表。
使用最近提出的一项技术来衡量得到的向量表征的质量,该度量指标不但期望意思相近的词表征相近,而且还能表示词的多种相似性程度(multiple degrees of similarity)。这常见于屈折语(inflectional language)中,例如名词可能有多种词尾(后缀),如果在原始的向量子空间中搜索相似词,可能找到的是具有相似词尾的词。
令人惊讶的是词表征的相似性远远超出了简单的语法规则。使用词偏置技术时,对词向量进行简单的代数操作,例如vector(“King”)-vector(“Man”)+vector(“Woman”)得到的向量与Queen比较近。
本文通过开发新的模型结构来最大化向量操作的精度,从而保留词间的线性规则。我们设计了一个综合的测试集从语法和语义规则两方面衡量,以此来展示该模型可以以很高的精度学习到许多规则,并进一步讨论了模型的训练时间和精度取决于词向量的维度和训练数据集的大小。
前期工作
将词表示为连续的向量的思想由来已久。一个很受欢迎的模型结构称为神经网络语言模型(neural network language model, NNLM),采用一个线性投影层加上一个非线性隐藏层来同时学习到词向量表征和统计语言模型。该工作得到后续很多工作的参考。
另一个有趣的NNLM结构是先用一个隐藏层的神经网络来学习词向量,再使用这些词向量来训练NNLM。因此,词向量的学习不需要构建完整的NNLM。本文对这个结构进一步扩展,致力于使用一个简单的模型来学习词向量表征。
后续会展示词向量表征可以用来显著改善和简化许多NLP应用。词向量本身的估计可以采用多种模型结构,在多种语料库上训练,其中一些学习到的词向量表征可以用作进一步的研究和对比。然而,据我们所知,这些模型的计算代价要远远高于最早的模型,一个例外是mnih2007three中提出的采用对角权重矩阵的log-bilinear模型。
模型结构
许多已经提出的不同的模型可以用来估计词的连续向量表征,包括广为人知的潜在语义分析(Latent Semantic Analysis, LSA)以及隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)。本文着重于用神经网络学习词的分布式表征,已有的工作表明,与LSA相比分布式表征可以更好的保留词间的线性规则。而LDA最大的缺点在于大数据集上的计算复杂度高。
比较不同模型结构,首先用完整的训练模型所需要的参数的数量来定义模型计算的复杂度。接下来试图最大化精度,同时最小化计算复杂度。对于下面所有模型,训练复杂度遵循:
其中\(E\)表示训练次数,\(T\)表示训练集单词数,\(Q\)表示模型结构进一步定义。通常\(E\)在3~50之间,\(T\)高达十亿。所有的模型采用随机梯度下降和反向传播。
前馈NNLM
概率前馈神经网络语言模型(Feedforward NNLM)包括输入(input)、投影(projection)、隐藏(hidden)、输出(output)四层。输入层中,前\(N\)个词编码为1-of-\(V\),\(V\)为词表大小。输入层映射到\(N\times D\)维的投影层\(P\)。由于在任何时刻,仅\(N\)个输入是激活的,因此投影层的组合是相对简单的操作。
NNLM结构的复杂计算在于投影层和隐藏层之间的计算,主要原因是投影层是稠密的。对于一个常见的选择\(N=10\),投影层\(P\)的大小可能为500~2000,而隐藏层\(H\)的大小通常为500~1000。更进一步讲,隐藏层通常用来计算在整个词表上的概率分布,输出层的结果是\(V\)维的。因此每个训练实例的计算复杂度为:
其中\(H\times V\)起决定作用。然而为了避免如此提出了一些实际的解决方案:使用Hierarchical Softmax,或者在训练的时候使用未归一化的模型来避免对模型的归一化。采用词表的二叉树表示,可以将输出单元的数量降低到\(\log_2(V)\)。这样模型的主要复杂度就在\(N\times D\times H\)了。
本文的模型采用Hierarchical Softmax,其中词表表示为霍夫曼树。这样做主要是基于之前观测到的一个现象:词频对于在NNLM上获取分类非常有效。霍夫曼树给频繁出现的词以较短的编码,这样进一步减少了输出单元的数量。而平衡二叉树需要\(\log_2(V)\)输出来评估,基于霍夫曼树的Hierarchical Softmax仅仅需要\(\log_2(Unigram_perplexity(V))\)。例如当词表大小为100万时计算效率得到了两倍的加速。虽然对于NNLM来讲不是最关键的加速,因为主要的计算瓶颈在于\(N\times D\times H\),后续提出的模型结构并没有隐藏层,而是主要取决于Softmax正则化。
递归NNLM
递归神经网络语言模型(Recurrent NNLM)的提出是为了克服前馈NNLM的一些局限性,例如需要指定上下文的长度(模型阶数N),因此理论上讲递归神经网络(recurrent neural network)可以比浅层神经网络(shallow neural networks)更高效的表示更复杂的模式。RNN并没有投影层,只有输入、隐藏、输出三层。这类模型的特殊性在于递归矩阵,该矩阵用时间延迟将隐藏层与自身连接起来。这就允许递归模型形式化某种短时记忆,因为之前的信息能够表示为隐藏层中的状态,该状态可以根据当前的输入以及上个时间步的状态进行更新。
RNN模型对于一个训练实例的时间复杂度是:
其中词表征\(D\)具有与隐藏层\(H\)相同的维度。我们同样可以使用Hierarchical Softmax将\(H\times V\)有效降低为\(H\times\log_2(V)\)。主要计算复杂度在于\(H\times H\)。
神经网络的并行训练
在大规模数据集上训练模型时,已经基于大规模分布式框架DistBlief实现了几个模型包括前馈NNLM以及本文中提出的新模型。该框架支持并行运行一个模型的多个副本,每个副本通过保持参数一致的中央服务器来同步梯度更新。对于并行训练,我们采用自适应的学习速率下的mini-batch异步梯度下降,整个过程称为Adagrad。在这种框架下,通常一个数据中心使用100多个模型副本,每个副本使用不同机器的多核。
对数线性模型
本节提出两个以最小化计算复杂度来学习分布式词表征的模型结构。前文观测结果表明:模型计算的主要复杂度来自于非线性隐藏层。尽管这些隐藏层使神经网络更优雅,本文还是决定使用可能没有神经网络数据精确的更为简单的模型,但是至少能够高效的训练更多的数据。
新结构的提出主要基于之前发现的NNLM可以通过两步进行训练:
- 使用简单模型学习连续词向量表征
- 基于分布式词表征训练N-gram神经网络语言模型
连续Bag-of-Words模型
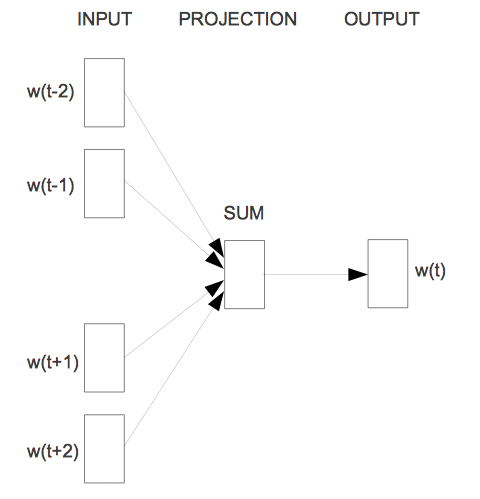
首先提出的结构类似于前馈NNLM,去掉了其中的非线性隐层,所有词共享投影层(不只是投影矩阵);所有的词投影到相同的位置(向量平均)。因为历史词序并不能影响投影,所以把这个结构称为词袋模型(bag-of-words)。更何况也使用了未来的词。在下节提到的任务中,使用4个未来词和4个历史词作为输入取得了最优的性能,其中优化目标是能准确对当前词分类。训练复杂度为:
将这个模型记为CBOW。与标准词袋模型不同,它使用上下文的连续分布式表征。注意输入层与投影层之间的权重矩阵与NNLM一样是所有词位置共享的。
连续Skip-Gram模型
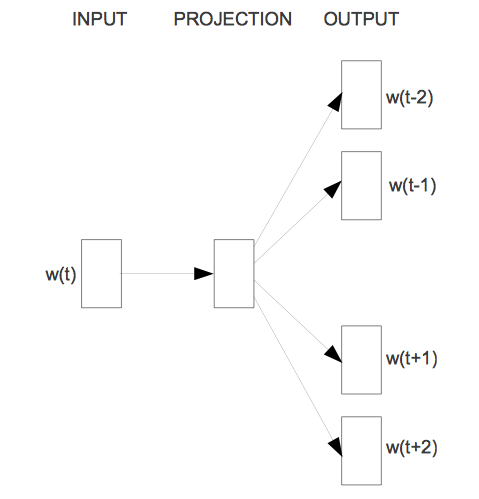
第二个结构与CBOW类似,不同的是CBOW基于上下文预测当前词,这个模型尝试根据同一句子中的另外一个词来最大化一个词的分类。更准确的说法,使用当前词作为有连续投影层的对数线性分类器的输入,来预测词语所在当前词的前后范围。发现增加窗口的大小可以提高学习到的词向量的质量,但也增加了计算复杂度。因为离得越远的词通常与当前词越不相关,所以给那些离得较远的词较小的权重使得其被采样的概率变小。该结构的训练复杂度正比于:
其中\(C\)为词间的最大距离,对于每个训练词从\(<1;C>\)范围内选择随机数\(R\),使用\(R\)个历史词与\(R\)个未来词作为当前词的标签。这就需要做\(R\times2\)个词分类,将当前词作为输入,\(R+R\)中的每个词作为输出。
-
本文作者:
Shintaku
本文链接:
https://www.shintaku.xyz/posts/word2vec/
版权声明:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Shintaku's Blog 。